
Episode 1: Myths, Challenges, and Solutions
Section 1. What is Federated Learning?
In recent years, Artificial Intelligence (AI) has revolutionized industries like education, business, finance, manufacturing, and healthcare by dramatically improving performance in areas such as personalized learning, fraud detection, workflow automation, and predictive diagnosis. Advances in data quality, storage, and algorithmic modeling now make it possible to create tailored AI solutions that enhance problem-solving efficiency.
With the rapid advancements, there is a growing need to integrate domain-specific solutions for improved models. Unfortunately, persistent misconceptions about AI—such as overreliance on centralized infrastructure and neglect of data privacy and ownership—pose risks and limit opportunities for development. These challenges are compounded by real-world concerns regarding data security and the need to build trust in AI systems. Addressing these challenges demands secure and collaborative AI development strategies. Federal institutions have implemented regulatory measures to ensure responsible AI practices. For example, the DoD’s Chief Digital and Artificial Intelligence Office (CDAO) released the Responsible AI Toolkit in 2023, a key milestone in the DoD’s Responsible AI Strategy, and the National Institute of Standards and Technology (NIST) introduced the AI Risk Management Framework in 2024, identifying risks in generative AI and proposing actionable solutions [1],[2]. Such initiatives underscore the importance of fostering secure collaboration to effectively tackle these issues.

Federated Learning (FL) emerges as a promising solution, by transforming how AI models are developed and deployed. FL is a distributed machine learning approach that trains models across multiple remote, private data sources while keeping data local to its source [3]. Unlike traditional centralized methods, FL aggregates model updates instead of raw data, ensuring privacy and reducing the risks associated with centralization. In an FL project, participants—referred to as “clients” or “nodes”—independently train a shared model on their local data. They send encrypted updates to a federated server for aggregation, and this process continues iteratively to produce a globally optimized model.
By eliminating the need for central data storage, FL ensures compliance with privacy regulations while leveraging data silos to generate actionable insights. Its decentralized framework is especially valuable in industries like healthcare and finance, where privacy and security are paramount. Moreover, FL dispels common misconceptions about AI and offers a scalable framework for secure, collaborative development.
To illustrate its potential, this paper will address prevalent AI myths and demonstrate FL’s ability to effectively tackle key challenges.
Section 2. Addressing AI Myths with Federated Learning
- Big Data Architectural Approach is Indispensable
The misconception that AI requires large, centralized data centers extends to the broader big data architecture, including centralized data warehouses, lakes, and marts. However, these beliefs often fail to account for the distributed nature of valuable data, leading to inefficient workflows, increased operational complexity, and amplified privacy concerns. Raw data holds value only when actionable insights can be derived, yet centralization often complicates this process. FL flips the paradigm by decentralizing AI development, enabling intelligence to be derived where data resides and eliminating the need for massive data transfers. This approach optimizes resource usage and fosters a more efficient, privacy-preserving AI ecosystem. By shifting the focus from monolithic architectures to decentralized frameworks, FL provides a smarter and more effective alternative for scalable AI innovation.
- Renovating Data Warehouses and Harmonizing All Data are Essential for AI
It is often assumed that building AI requires overhauling data warehouses and harmonizing all data elements, but this approach results in high costs, time demands, and lack of scalability. FL provides an alternative by enabling organizations to collaborate without fully harmonizing their data. Admittedly, while FL platforms can facilitate AI training through a unified data governance system built on a Common Data Model (CDM), achieving convergence on such models and associated policy-driven governance remains a non-trivial challenge. Stakeholders often have competing interests, making alignments on data models, schemas, and governance frameworks complex and resource intensive. FL helps mitigate these challenges by allowing decentralized collaboration where minimal alignment suffices, but it is not a universal solution. Organizations must still navigate stakeholder dynamics and invest in fostering agreements on shared data usage policies and interoperability to realize the full potential of FL.
- Privacy Issues Can be Solved by De-Identifying Data
Once data is shared, tracking its secondary use becomes nearly impossible, further discouraging providers from sharing data due to the lack of economic value and transparency. Additionally, unverifiable data sources undermine the explainability of AI models. FL offers a robust solution by addressing privacy concerns while also ensuring visibility into data provenance and lineage. By allowing 100% control of data by the originator, FL not only protects privacy but also ensures transparency in data origins, transformations, and usage throughout the AI development lifecycle. This inherent traceability enhances trust in collaboratively trained models and resolves uncertainties often associated with traditional AI approaches reliant on de-identified data. Furthermore, FL enables participants to retain ownership of their data assets, promoting economic value while fostering a secure and collaborative AI ecosystem.
- Open Data Alone is Sufficient to Improve Model Performance
Relying solely on open data to enhance model performance comes with limitations. While open benchmark datasets provide a starting point for model evaluation, they frequently lack the granularity and domain-specific insights needed to tackle complex problems effectively. Defining metrics that address real-world challenges is often more impactful. FL enables fine-grained insights by leveraging domain-specific data directly from its sources, ensuring models are trained with nuanced, context-aware information. FL also fosters collaboration within communities of interest, co-opting domain stakeholders to enhance the robustness and relevance of AI models. FL’s collective approach bridges gaps left by open data, delivering richer insights and more impactful solutions tailored to specialized challenges.
The following features summarize how FL addresses data privacy and security challenges, and demonstrate its significant potential and importance in building robust AI models.
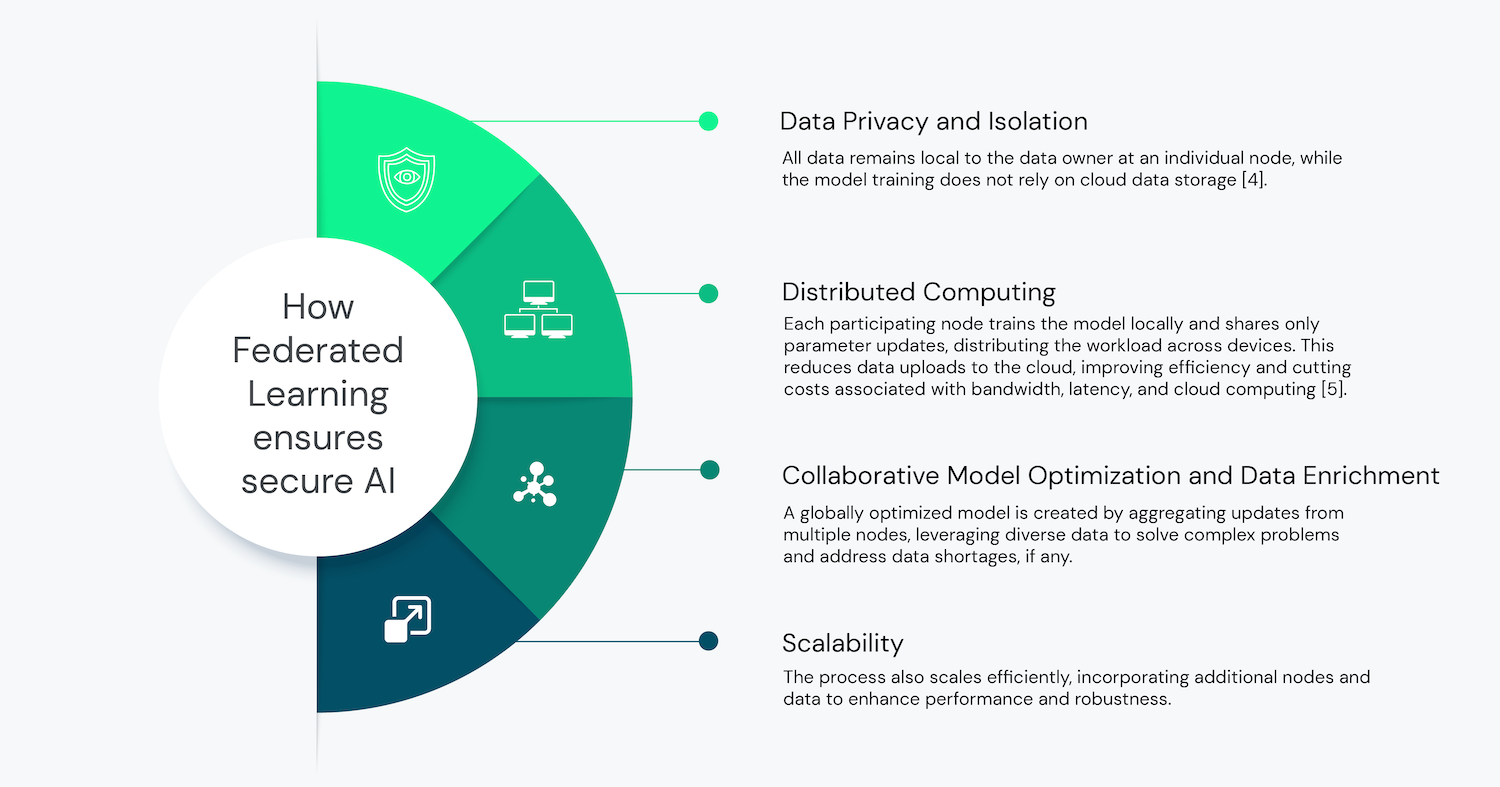
FL thus offers immense potential for privacy-preserving and scalable AI models, particularly for industries where data centralization is complicated – or prohibited — by privacy, regulatory, competitive, and budgetary constraints [6].
The graphic below illustrates the architecture of an FL system, showcasing its ability to perform distributed learning and address potential data deficiency challenges.
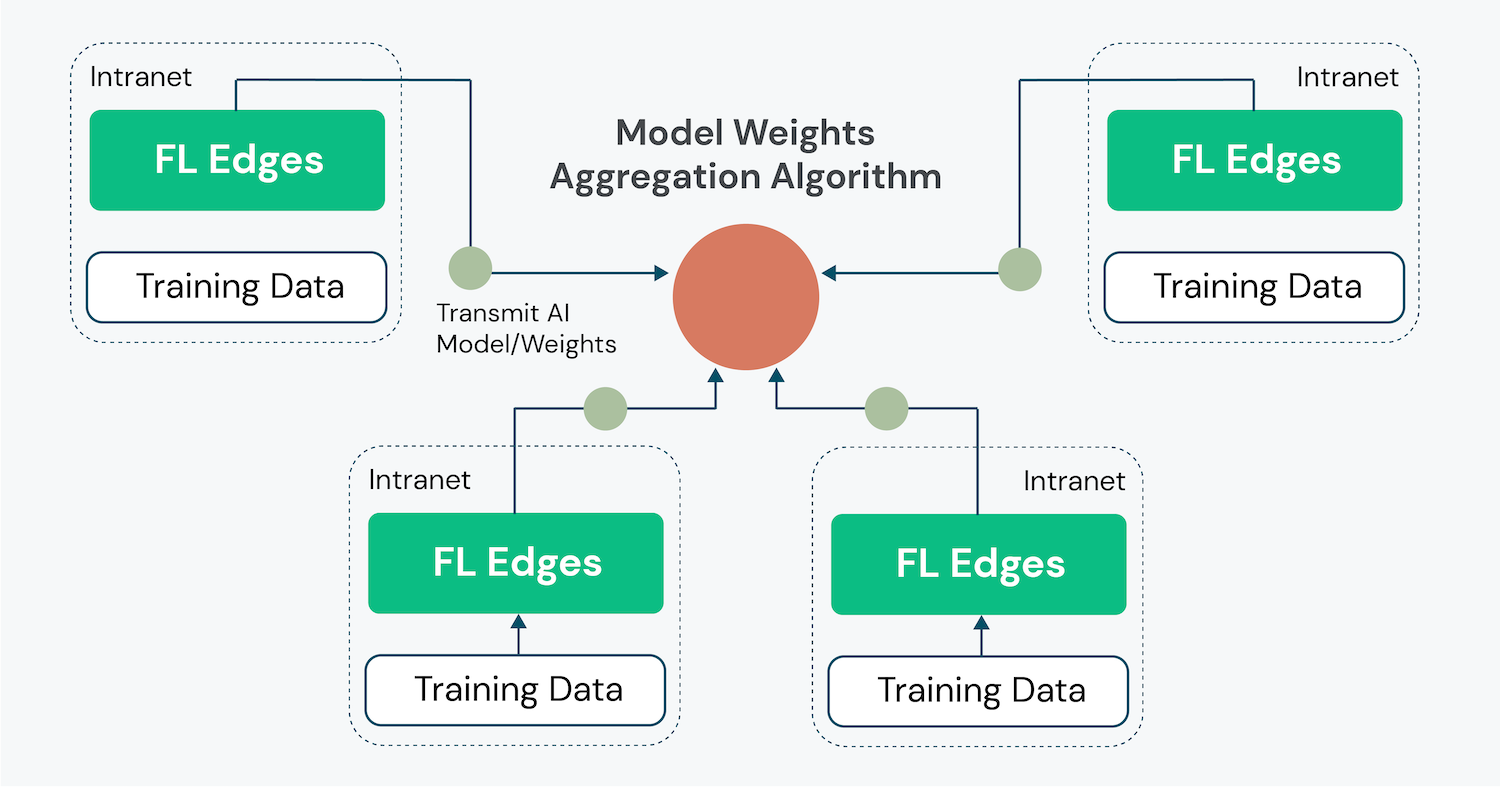
Section 3. Detailed Federated Learning Workflow
The FL workflow operates on a hub-and-spoke model, where a central FL server orchestrates communications with multiple client nodes. The process involves:
- Initialization: All parties receive invitations to participate in an FL project and register as participants [7].
– The FL server hosts a predefined model and announces the training task to participating nodes.
– After validation, a subset of nodes is selected and assigned a training schedule based on available resources and priorities. A unique token is provided to each node to identify its contribution throughout the FL training process [8].
- Local Training: Client nodes independently train the model on their local data and send encrypted updates back to the server.
- Aggregation:
– The server aggregates these updates using secure methods, such as Federated Averaging, which incorporates updates proportionally based on the size of each node’s local dataset [9].
– Aggregation combines insights from all participating nodes to create a globally optimized model.
- Iteration: In each iteration, the FL server manages communications, system configurations, and model synthesis routines.
– After aggregating updates, the updated global model is redistributed to nodes for further local training in subsequent rounds.
– The cycle repeats until the model meets predefined performance criteria.
- Final Deployment:
– The resultant aggregated model is then automatically validated at each node for generalizability.
– Once optimized, the final model can be deployed across participating nodes or centralized systems as needed.

The core principle of federated learning (FL) lies in collaborative model training, where nodes and the server exchange model updates instead of raw data [10]. This approach transforms traditional centralized machine learning by reducing the risk of sensitive data exposure, efficiently distributing workloads, enriching data sources, and building robust, trustworthy models. By minimizing the likelihood of information leakage, FL is particularly well-suited for sectors requiring stringent data security. Additionally, FL ensures model trustworthiness through multiple mechanisms, including the integrity of local data verified via provenance tracking, secure architecture features such as homomorphic encryption and differential privacy, and robust validation through cross-node performance checks. Collaborative governance and stakeholder consensus further enhance trust by ensuring transparency and shared accountability.
Section 4. DSFedTM – DSFederal’s All-Inclusive Federated Learning Platform
Making FL practically accessible remains a key challenge, as building an FL system from scratch is complex and resource intensive. To address this, DSFederal has developed an all-inclusive Federated Learning Platform, DSFedTM — a ready-to-use solution designed for simplicity and collaboration.
DSFedTM functions as a collaborative media hub, enabling users to create accounts, initiate FL projects, and invite partners to contribute data for collaborative model training.
Key features include:
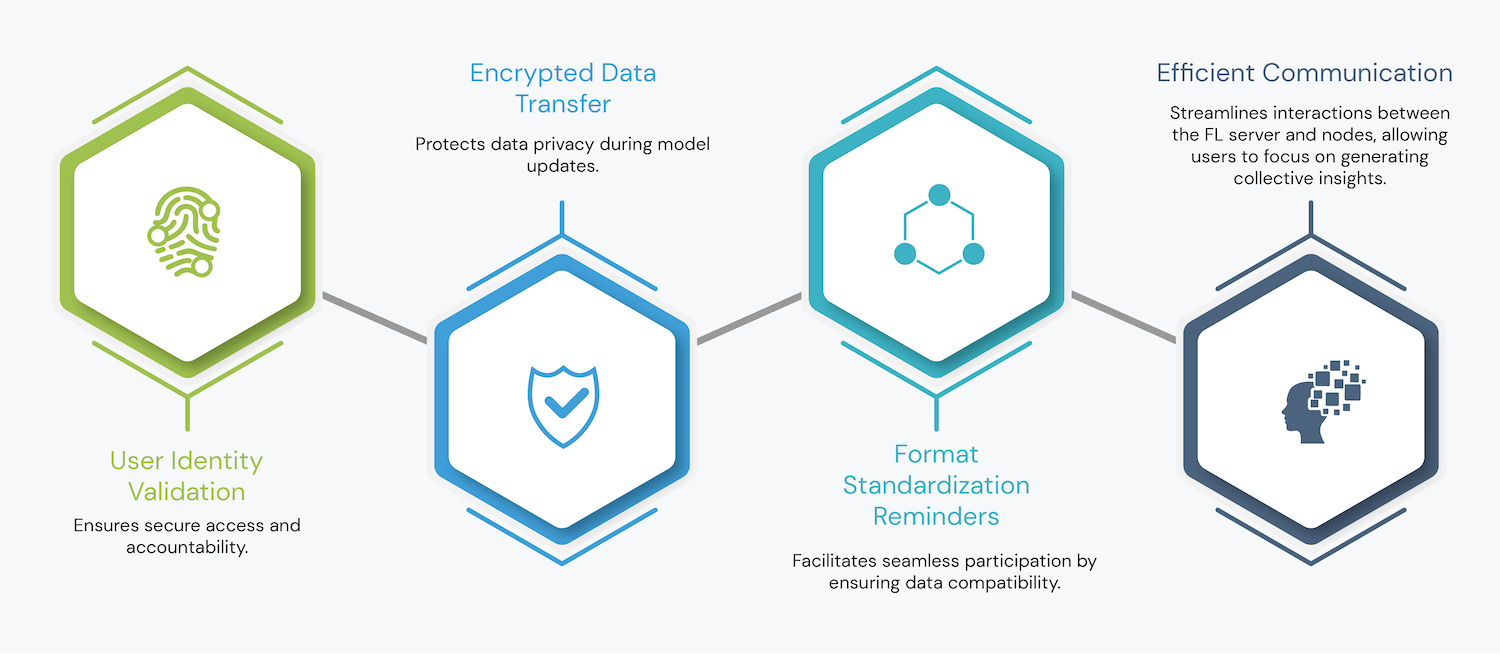
The platform’s low-code, ready-to-deploy infrastructure empowers users—including those unfamiliar with FL—to initiate secure, collaborative modeling projects with ease. By lowering technical barriers, the FLP redefines FL-based AI development, fostering actionable insights while maintaining data security and ownership.
Section 5. Conclusion
While AI continues to transform industries and solve complex challenges, its potential must be harnessed responsibly to ensure privacy, fairness, and trust. FL will play a crucial role in achieving these goals by enabling secure collaboration while preserving data ownership.
At DSFederal, we believe FL is the key to unlocking the next wave of AI innovation. With DSFedTM, organizations can unlock new possibilities, creating transformative and trustworthy AI solutions. Through FL, we aim to enable AI to tackle real-world challenges with enhanced privacy, security, and collaboration, laying a strong foundation for responsible and impactful technological advancements. We hope you have found valuable information in this inaugural episode of our FL series. In Episode 2, we will delve into how FL integrates with specific models and frameworks, highlighting those that benefit most from FL’s capabilities. We’ll also showcase practical applications that demonstrate the transformative impact of DSFederal’s FLP.
Contributors
Shijia Huang, Data Scientist – Primary Author
Clement Chen, Advisory Board Member – Reviewer
Chia-yun Chang, Data Scientist Lead – Reviewer
References
- U.S. Department of Defense, “CDAO releases Responsible AI (RAI) Toolkit for ensuring alignment with RAI best practices,” U.S. Department of Defense, Nov. 14, 2023. https://www.defense.gov/News/Releases/Release/Article/3588743/cdao-releases-responsible-ai-rai-toolkit-for-ensuring-alignment-with-rai-best-p/
- National Institute of Standards and Technology (NIST), “AI risk management framework,” NIST, Nov. 12, 2024. https://www.nist.gov/itl/ai-risk-management-framework
- K. Martineau, “What is federated learning?,” IBM Research, Aug. 18, 2023. https://research.ibm.com/blog/what-is-federated-learning
- “Federated Learning for privacy-preserving edge computing,” Dialzara.com, May 25, 2024. https://dialzara.com/blog/federated-learning-for-privacy-preserving-edge-computing/
- M. Cole, “Have your cake and eat it, too: federated learning and edge computing for safe AI innovation,” IAPP, Jun. 5, 2024. https://iapp.org/news/a/have-your-cake-and-eat-it-too-federated-learning-and-edge-computing-for-safe-ai-innovation
- C. Hacks, “Federated Learning: a paradigm shift in data privacy and model training,” Medium, Dec. 01, 2024. https://medium.com/@cloudhacks_/federated-learning-a-paradigm-shift-in-data-privacy-and-model-training-a41519c5fd7e
- Taiwan AI Labs, “What is Taiwan AI Labs federated learning framework?,” Taiwan AI Labs FLP FAQ, 2023. https://harmonia.taimedimg.com/flp/documents/faq/ch9/9-1-what-is-taiwan-ai-labs-federated-learning-framework
- NVIDIA, “Federated learning FAQ, ” NVIDIA Docs, 2020. https://docs.nvidia.com/clara/clara-train-sdk/federated-learning/fl_faq.html
- B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. Y. Arcas, “Communication-efficient learning of deep networks from decentralized data,” PMLR, Apr. 10, 2017. https://proceedings.mlr.press/v54/mcmahan17a.html
- G. A. Kaissis, M. R. Makowski, D. Rückert, and R. F. Braren, “Secure, privacy-preserving and federated machine learning in medical imaging,” Nature Machine Intelligence, vol. 2, no. 6, pp. 305–311, Jun. 2020, doi: 10.1038/s42256-020-0186-1.


